
La idea de hacer un buen “show me the code» no es del todo mala: ver el código fuente de un proyecto te permite descubrir si puede dar problemas a la hora de mantenerlo; así como si va a tener problemas de seguridad o de eficiencia. También puede ser útil para peritajes. O para evaluar la habilidad de un programador al que queramos contratar para que nos haga un programa.
Lo primero que debemos hacer es librarnos de ideas preconcebidas: si tomamos una base de código lo suficientemente grande, y miramos con una ventanita lo suficientemente pequeña, vamos a encontrar lo que busquemos.
Una vez que nos hemos librado de prejuicios, el siguiente paso será tomar código desarrollado por la persona. Esto es importante, porque si hacemos un análisis sobre código de una persona distinta de la que queremos estudiar, no estudiaremos a la persona sobre la que tenemos interés. En el caso de proyectos de software libre, esto es especialmente delicado: es normal que un programa esté realizado por muchas manos. El software libre es con frecuencia colaborativo, y podemos quedar en ridículo con facilidad si no sabemos identificar la autoría de un trozo de código.
El primer paso es abrir el archivo, y mirar en la cabecera. Los programadores de software libre suelen indicar en la cabecera del código quién es el autor. Por ejemplo, si tomamos un programa al azar, como pueda ser este, vemos que el autor lo tenemos en la cabecera:
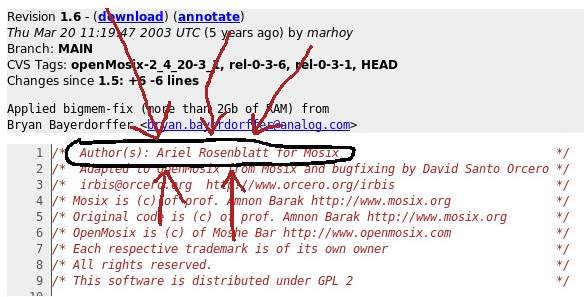
(Está marcado con un circulo y unas flechitas por si algún chaval de 20 años o algún blogero influyente de la A-list tienen problemas en encontrarlo).
Bueno, ya sabemos el autor al que debemos achacar el problema. Pero esto no tiene importancia, porque acabamos de encontrar un posible problema de seguridad que nos parece gravísimo. Lo adecuado aquí es recordar que el CVS es una instantánea en el pasado de un proyecto, y que el problema puede ya estar solucionado. Seguimos con la imagen:
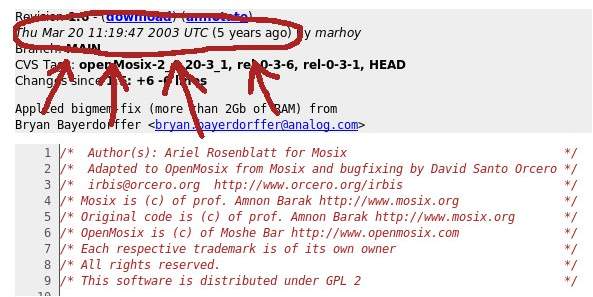
(Está marcado con un circulo y unas flechitas por si algún chaval de 20 años o algún blogero de la A-list tienen problemas en encontrarlo. Para ellos va también la explicación de lo que es un CVS, por si lo desconocen).
Bueno, esto parece que tiene cinco años… Y nadie parece haber tocado el código en cuatro años… o el proyecto está muerto hace cuatro años, o ya nadie usa ese CVS. ¿Que hacemos? Preguntar al mantenedor cual es la versión más reciente. Si no, podemos estar dando un parte de seguridad de un error que puede que fuera corregido hace tres años, y que el CVS no lo utilice nadie desde hace cuatro años. Especialmente si es un proyecto cuya historia desconocemos y no nos hemos tomado la molestia de informarnos.
Supongamos que con la emoción de un chaval de 20 años que ha encontrado un error de seguridad en un paquete con una complejidad que no entiende, queremos dar un parte de seguridad por el problema. ¿Que hacemos?
Niños, vamos a aprender un concepto clave: como se dan los partes de posibles vulnerabilidades.
- Primero, se avisa al desarrollador del paquete con un correo, avisándole del problema. Lo más normal es que genere el parche y saque una nueva versión al momento.
- Entonces, avisamos a los canales comunes de seguridad para administradores de sistemas, para que la gente actualice el paquete. Si el desarrollador no ha escuchado, es una buena idea -en el mundo del software libre, al menos- que hagamos el parche de seguridad.
- Finalmente, cuando la vulnerabilidad tiene parche que protege el sistema, y los administradores pueden acceder al parche, se notifica a los medios masivos -tipo meneame-.
La gracia está en el orden de los pasos. ¿Porqué? Porque lo primero en estas cosas no es el ego; sino la ventana de vulnerabilidad que se crea dando la noticia antes de que haya parche, y que pueda ser alegremente explotada. En software privativo solo podríamos avisar de los síntomas. En software libre tenemos la ventaja competitiva de que podemos arreglar los problemas en cuanto los detectamos. Si somos buenos ciudadanos del ecosistema de software libre podemos aportar la solución al momento.
¿Como no se hacen las cosas? Pues al revés; primero lo notificas en meneame, un día más tarde, lo mandas a bugtraq, donde un blogger de la A-list -que participaba en la discusión de meneame- se hace eco del problema. Y al mantenedor del paquete ¿para que avisarlo? Que se joda, es uno de los imbéciles que desarrolla software libre. Si cae algún sistema por la vulnerabilidad en su código, mejor, uno menos de estos cabrones del software libre. Más carne para que muerda el blogger.
Todo esto le puede pasar a un hipotético chaval de 20 años que no lleve suficiente tiempo en esto del software como para saber que los avisos de seguridad se hacen así por algo. Lo peor que puede pasar es que nuestro chaval de 20 años sea un lince, y haya descubierto un error: miles de sistemas vulnerables durante una noche. Daños económicos cuantiosos. Pérdida de datos. Cuando el mantenedor del paquete de software libre se despierte al día siguiente, será demasiado tarde. Objetivo cumplido.
Pero lo mejor que suele ocurrir es precisamente lo que es normal, cuando estas cosas las hace un hipotético chaval de 20 años calentado por un blogger de la A-list. Especialmente si no está claro como explotar la vulnerabilidad, y apenas realiza una búsqueda con grep de las funciones en C que todos sabemos que potencialmente puedan tener problemas de seguridad. Si hubiese contactado con el desarrollador de software libre a cargo del paquete -cuyo teléfono movil está en su web- se habría enterado que:
- El código original de MOSIX tenía muchos errores. Ese, y otros que el chaval ni ha identificado.
- El mantenedor dejó de mantener la versión del CVS porque la prioridad en el CVS era el desarrollo de nuevas funcionalidades, por encima de lo que él consideraba más importante: corregir esas guarradas como precisamente la que ha encontrado el chavalote.
- Mantiene una versión propia del paquete, liberada, desde hace cinco años.
- Que ese problema es extremadamente difícil de explotar por como se utiliza la biblioteca, pero que el potencial problema fue eliminado en la versión del paquete de nuestra víctima hace más de tres años.
- Que el proyecto está oficialmente cerrado.
- Finalmente, que si se toma la molestia de ver las descargas en el sitio web que se pueden encontrar aquí verá que el número de descargas del kernel y de las herramientas de área de usuario debería casar -unas no funcionan sin las otras-, pero no casan. La razón: que se utiliza la versión del desarrollador -y no la oficial- desde hace años de forma mayoritaria, por lo que la mayor parte de los sistemas no son vulnerables. Lo que hay que avisar es que los que usan las herramientas del CVS se deben pasar a las herramientas del objetivo de nuestro “show me the code»
Si hubiese contactado primero con el mantenedor del paquete, cosa que se puede hacer en software libre y no en el privativo, el chaval de 20 años habría aprendido un montón de cosas. Además, probablemente hubiese recibido una felicitación por parte del desarrollador de software libre -promete mucho con su edad y siendo capaz de llegar a ese punto, por identificar un problema potencial y saber gestionar la crisis-. Hubiese ganado un amigo. De esas redes de contactos va el software libre. No ha dado una falsa alarma -ya que la rama mayormente usada de ese paquete no tiene el problema-. Incluso el desarrollador le hubiese ayudado a rellenar la entrada en los canales de notificación respecto a la otra rama de código, para evitar que el chaval cometa algún error conceptual:
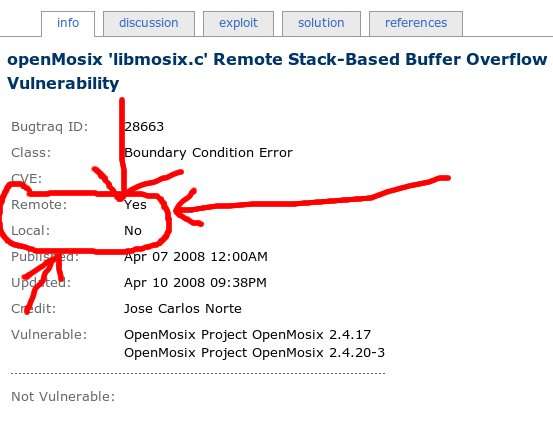
El error potencialmente es un buffer overflow de una aplicación local, que no toca red, no es servidor, no abre un socket; por lo que no deberías marcarlo como explotable remotamente. Además, por no consultar puede ocurrir que te saquen los colores en la propia lista de seguridad. Por cierto, nixpanic -el que le saca los colores a nuestro chaval- no es alumno ni empleado mío. Este es su perfil en linkedit. Se dedica a desarrollar drivers para linux.
Pero a lo que íbamos: puede ocurrir que, después de analizar el código, encuentres algo que te parezca extraño. No erróneo, sino extraño:
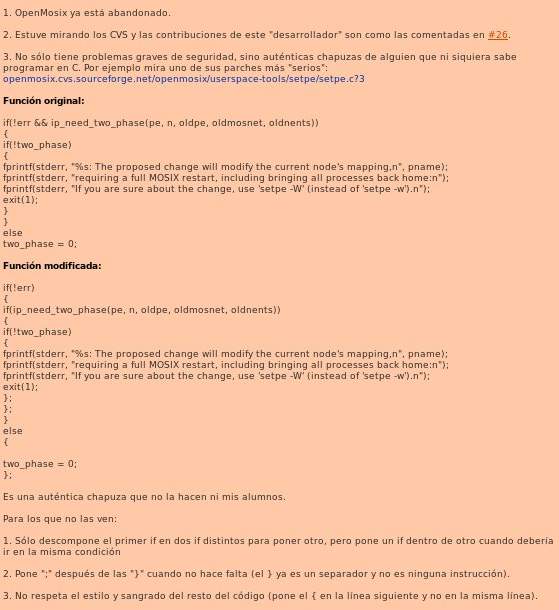
(bueno, esto está escrito por el blogger influyente de la A-list… Sí, para él, poner un punto y coma de más es un error grave, y la tabulación muy grave)
Cualquier desarrollador con experiencia en sistemas grandes y complejos sabe que muchas veces encuentras “legacy code» con características raras. Para cualquier persona con experiencia real en ingeniería inversa -en el caso del que escribe estas líneas, que gané dicha experiencia leyendo tochos en Fortran de programas de física computacional hechos por el director de tesis de mi director de tesis, hace eones y sin documentación-, sabe que las cosas extrañas que aparecen en el código suelen ser soluciones ad-hoc a bugs muy difíciles de localizar.
¿La solución? Enfundarse el ego, localizar al autor, y preguntarle el porqué de una línea.
Su contestación puede ser una sarta de absurdidades -en cuyo caso, ya sabemos que no sabe C-, o comentarnos el porqué del problema. Conociendo la forma de ser de los desarrolladores, probablemente incluso tengamos que aguantar una batallita de como localizó el error. Es el problema de la gente que disfruta con su trabajo.
En este caso particular, el problema estaba en el optimizador del gcc. En la versión del compilador que empleaba en la época, había reportes de errores que estaban causados porque con O3 el compilador se empeñaba en ejecutar la función ip_need_two_phase, función que generaba efectos laterales. Según el estándar de C, if(a&&b) debería ser equivalente a if(a)if(b). Esto no debería ocurrir, pero ocurría. Un error difícil de localizar; pero, una vez localizado, el arreglo era trivial y el código arreglado se ve estúpido. El problema lleva años corregido en el gcc. Pero el código así desarrollado es correcto -quizás feo- pero funciona perfectamente en compiladores con y sin el problema.
Bueno, parece que de este código que hemos analizado desde el principio no hemos sacado nada. En parte, porque era un programa muy grande, en el que mucha gente metió mano. También porque el mantenedor ha dicho numerosas veces en público que gran parte del código está heredado de MOSIX, que este código tenía este tipo de problemas y que estaba sajándolo de errores. Quizás debíamos haber ido a por la versión desarrollada por nuestro objetivo. Vamos a tomar código de un proyecto que solamente él haya metido mano.
Encontramos una joyita: un programa de casi 18000 líneas de código escrito en dos lenguajes -C importando con extern C y C++- en su versión 0.6, sobre el que la persona objetivo reclama la autoría completa. Falta apenas una cosa que no obtendremos: la documentación del análisis y los requisitos. Esto puede ser un problema; porque es difícil evaluar quien corre mejor o más rápido si nadie sabe cual es la meta. Pero bueno, hay cosas que se pueden verificar sin eso.
Entramos en el código, y vemos algo raro. Dejando a un lado que parte del programa está en C, y se incluye con extern C, y parte está en C++. El autor en numerosos puntos del programa en lugar de sumar una cantidad prefijada a un puntero, lo incrementa varias veces. Para que hasta el blogger prestigioso e influyente de la A-list o el chaval de 20 años puedan entenderlo, es como si en lugar de hacer:
4+3=7
Hacemos:
4+1+1+1=7
Evidentemente, no vamos a morder como un dóberman aquí, reclamando que esto es un error. Primero, porque no lo es: el programa es correcto. Podemos reclamar que esto es una guarrada, y que es un programador guarrete. Pero el hecho de que los punteros se puedan referenciar muchísimo más legible y cómodamente de otra forma, y que lo normal es que la persona con limitados conocimientos en programación desconozca precisamente la forma de operar con los punteros que emplea nuestro objetivo, debería llamarnos la atención. No es que programe como si desconociera la aritmética de punteros, sino que emplea la aritmética de punteros de forma pedante e inusual, mucho más compleja de lo que parece necesario. Probablemente, como en el caso anterior, nos estamos perdiendo algo.
Como somos profesionales serios, contactamos con el desarrollador. Su contestación puede ser una sarta de absurdidades -en cuyo caso, ya sabemos que no sabe C-, o comentarnos el porqué del problema.
El problema está en lo que no tenemos: los requisitos. El programador nos cuenta que hay programas de software como OsiriX que tienen un soporte completo a ficheros en formato DICOM, pero que la plataforma sobre la que se ejecutan es muy cara -Mac OS X-. Que comenzó siendo una práctica del programa de doctorado; pero que se encontró con la sorpresa de que tuvo una ingente cantidad de descargas, y correos de agradecimiento: el programa estaba siendo usado en regiones con escasos recursos en Sudamérica y África. Una práctica de doctorado se acababa de convertir en algo con utilidad social. La reclamación que todo el mundo hacía es que era demasiado lento. Por ello, la solución fue reescribir el código del renderizador de DICOM; de tal forma que fuese muy eficiente en máquinas antiguas. El autor del programa puede que ya fuese perro viejo optimizando programas de cálculo numérico, por lo que tenía trucos en la recámara. Y este era uno de ellos.
Supongamos que no nos fiamos y desconocemos los rudimentos de la optimización en este tipo de programas. En ese caso, pedimos pruebas de que esto es así. Al desarrollador de software libre hasta le hace gracia que se lo pidamos -puesto que es un clásico de las optimizaciones-, y nos manda un código en C:
void main()
{
char *psaux=0;
long int j=0;
for (;j<60000000;j+=2)psaux++;
printf("%d",psaux);
}
Lo compilamos -como nos dice- con -S y empleando -march para forzar código para una plataforma antigua -un athlon mismo nos vale-, y obtenemos algo como:
.L10:
cmpl $59999999, %eax
jle .L3
CÓDIGO RESTO PROGRAMA
.L3:
incl %ecx
addl $2, %eax
jmp .L10
con código optimizado con -O2, y:
.L10:
cmpl $59999999, %eax
jle .L3
CÓDIGO RESTO PROGRAMA
.L3:
incl -12(%ebp)
addl $2, %eax
jmp .L10
Si compilamos sin optimizar. En máquinas de 32 bits, el compilador genera un incl DESPLAZAMIENTO(%ebp), y optimizando -que es la opción por defecto en kradview-, genera un incl %REGISTRO. Entonces sabemos que nuestra víctima del show me the code tenía razón: incrementar el puntero es incrementar un registro; mientras que sumar un número supone leer al menos un entero de 32 bits de memoria, meterlo en registro y sumarle uno. Aunque en una máquina moderna la velocidad es similar, en una máquina que ya tenga algunos años la diferencia de velocidades es abismal. Una optimización guarrilla, pero que funciona.
Aquí podemos avisarle que está incrementando una variable que ya no utiliza. Probablemente nos lo agradezca, diga que se utilizaba para algo entre los paux++ antiguamente, pero que el código se retiró; pero también puede que nos diga que llegamos tarde, y que faltaban un par de días para liberar la próxima versión de la aplicación. En la versión nueva, de más de 30000 líneas de código, sigue haciéndose esta optimización con punteros. Pero esa variable ya no está.
Nos faltaba, pues, conocer los requisitos: una vez conocidos, podemos discutir la priorización de eficiencia sobre legibilidad, o el hecho de liberar código sin pasar el comando indent sobre él. Pero podemos darnos una idea de que es un programador pragmático y con recursos.
Evidentemente, esto puede pasar en también otros aspectos del programa: como el hecho de que nuestro programador emplee flush en algunos lugares elegidos; cuando emplear setlinebuf() llamada una sola vez al principio del programa es un castigo muy grande para el rendimiento en máquinas antiguas: el objetivo no es poner el stream como unbuffered siempre, sino solamente cuando es imprescindible. O haya algún archivo al que al programador se le hubiera olvidado pasar el indent para ajustar las tabulaciones -para el blogger: es un programa que genera automáticamente las indentaciones correctas-. Evidentemente, ni mencionaremos como crítica que sea algo pedante escribiendo código, poniendo siempre punto y coma después delif para asegurarse que no se despistará con los else, o que ponga paréntesis de más -cosas que no afectan al rendimiento, pero sí a la legibilidad, mejorándola-: al fin y al cabo son cosas que mejoran la legibilidad sin tener coste de rendimiento, y no vamos a reclamar a un programador por ello.
Bueno, la verdad es que esto son solamente algunas líneas genéricas sobre como hacer bien un “show me the code» si queremos una impresión real y objetiva de cómo es un programador. Pero lo más importante es lo que comentamos al principio: olvidar los prejuicios. Pero si buscamos una nube con forma de cerdito, terminaremos encontrándola.
Finalmente, si nuestra intención no es esa, sino utilizar nuestro poder para transmitir mensajes y movilizar con un objetivo: atacar a un desarrollador de software libre comprometido, con más de un centenar de miles de líneas de código liberadas en varios proyectos estratégicos para la comunidad, la mejor guía os la puede dar un blogger de la A-list aquí. Después de ejecutada, aunque el ego del blogger A-list sea un poquito mayor, y estará un poquito más tranquilo de que nadie en la comunidad del software libre se atreverá en el futuro a no reírle las gracias, habrá creado un peligroso precedente sobre la relación que debe tener un desarrollador de software libre con su código liberado, y ha abierto el camino para que los desarrolladores de software libre tengamos alguna preocupación más que no tienen los de software privativo. Es muy fácil tomar un programa que ahora ya va por más de 30000 líneas de código en su última versión, sacar media docena de líneas de contexto y, desconociendo completamente porqué se ha optado por ello, atacarle personalmente. No es posible estar justificando cada docena de líneas que te descontextualizan en un texto de 20000 caracteres . Simplemente, no todos tenemos el tiempo de estar defendiéndonos de gente con ganas de tumbar a personas y proyectos.
Un mensaje final para el blogger de la A-list: Si no te gusta mi código, mándame un parche para arreglar lo que no te guste. Se constructivo.
Si te sentías ofendido personalmente, sigue sin ser justificable. Literalmente, dije: “Porque antes entrará Chikilicuatre que un Ingeniero en Informática en la Comisión Interministerial de la Sociedad de la Información y de las Nuevas Tecnologías en España. Y siempre habrá un Ricardo que dirá que aprendió más informática afinándole la guitarra a Chikilicuatre que en cinco años de Ingeniería Informática.», tú con tu gran capacidad de comprensión lectora entiendes que te he llamado ingeniero de Chiquilicuate. Fuistes tú el que has dicho en tu blog, en la entrada que te contesto, todo lo que no has aprendido dentro de la carrera. Yo me he limitado a señalar que lo que tu dices que no aprendistes en tu universidad privada, yo sí lo he estudiado en una universidad pública andaluza, donde he recibido una formación de nivel. De hecho, comento mi convencimiento de que estas cosas se estudian en Argentina. Un gran científico como tu debería ser capaz de entender un texto como este, y entrar en una discusión constructiva. Por cierto, respondes insistentemente lo de que todos te atacamos vía “ad-hominem�?. Pero debes tener en cuenta que eres tú el que emplea, como único argumento en cualquier discusión, la gran autoridad que tienes como gran figura “blogger chachi»/“gurú software libre»/“gran empresario-técnico meneame»/“científico con cuarenta publicaciones». Y cualquier discusión de tus argumentos, como se centran en tí, en tus dichos, tu sabiduría y tus anécdotas sobre tí, terminan tocándote. Es más sencillo declarar en la blogosfera: no tomarás en nombre de Gallir en vano.
Te respeto como persona -como a todas las personas-. Respeto tu aportación al software libre -como respeto a todos los que colaboran: haciendo contribuciones tan alucinantes como la tuya, tan miserables como la mía-. De hecho, a mí me parecen respetables todas las contribuciones, aunque sea traduciendo tres líneas de un fichero de configuración. A tí, veo que no. Defiendo el respeto a los desarrolladores de software libre, como ya los defiende toda la comunidad.
Otra cosa es que tú y yo tengamos una discusión sobre un tema concreto. En este caso, sobre el nivel formativo de los estudios de Ingeniería en Informática, y sobre si un Colegio de Ingenieros en Informática es bueno o no para la sociedad -colegio que en muchas autonomías españolas ya es una realidad legal-. Pero discrepamos sobre una opinión manifestada en una entrada a tu blog: Entrada en la que tú mismo dices de tu propia boca lo poco que aprendiste estudiando tu carrera; no lo digo yo, lo has dicho tú mismo. Me he limitado a repetir lo que tú dices, y añadir que yo sí que lo he estudiado en mi universidad, y que estoy muy orgulloso de haber estudiado Ingeniería Informática en una universidad pública de mi tierra.
Por mucho que discutamos, aunque me insultes -que yo no creo que te haya insultado- no te voy a hacer un show me the code como el que tu me has hecho. Si algún día te audito tu código, te va a llegar un parche por correo electrónico, corrigiendo tus errores. Esa es la diferencia entre la critica destructiva y la constructiva. El problema no es que hayas mostrado mis vergüenzas, sino que no eran tales. El problema es que termina siendo mi capacidad de dar credibilidad contra la tuya, frente a gente que puede no entender los listados de código. Es un problema de popularidad, no un problema de buen código. El problema es que no tengo trabajo asegurado de por vida; soy un profesional de la Ingeniería Informática, lo que no me permite quedarme impávido. Por otro lado no tengo todo el tiempo del mundo para hacer siete páginas de explicación cada vez que alguien como tú decide que saca doce líneas de contexto y me pone a parir. Si quieres hacerlo, estupendo. Es un país libre. Pero luego no tengas la poquísima vergüenza de erigirte en paladín del software libre y speaker de la FSF para pontificar sobre lo divino y lo humano, cuando para cualquier persona con dos dedos de luces es aterradora la idea de que una persona con tu capacidad de difusión de información pueda hacer este tipo de cosas.
Hace una semana pensaba que Ricardo Galli tiraba piedras contra el tejado de la Ingeniería Informática. Ahora creo que las tira contra la Ingeniería Informática, contra mi profesión, y además contra el software libre. No porque yo sea el software libre, sino porque los métodos de Ricardo para asegurar que nadie ose discutirle las opiniones son dañinos para todos. Pero igual que cuando las tiras contra el tejado de mi profesión la gente se ha revelado, y no tienes credibilidad entre los Ingenieros en Informática, con actitudes como esta quemas tu credibilidad como autoproclamado paladín del software libre.
Tags:ciencia, legales, software libre, ética,colegios informáticos, David Santo Orcero, Ricardo Galli,deontología, programación básica.
